

Ever notice how Google starts suggesting searches before you finish typing? Or how your phone predicts the next word you'll type? Behind these seemingly magical features lies a powerful data structure called a trie. From predictive text to network routing, tries are the silent powerhouses making our digital experiences seamless.
This data structure is also a popular choice in tech interviews at companies like Google (autocomplete design), Meta (word search), and Amazon (spell checkers) - making it essential knowledge for developers.
The Problem: Speed vs Space
Traditional text search methods face a fundamental challenge. Storing complete strings in arrays or hash tables works for small datasets, but falls apart when dealing with:
Millions of search queries per second
Real-time word predictions
Network routing tables with billions of IP addresses
Dictionary lookups across multiple languages
What Makes Tries Special?
Unlike binary trees or hash tables, tries (pronounced "try" or "tree") are built specifically for string operations. They excel at:
Prefix Matching: Find all words starting with "pro" instantly
Memory Sharing: Common prefixes are stored once, saving space
Ordered Access: Words are naturally stored in alphabetical order
Character-by-Character Navigation: No need to process entire strings
Anatomy of a Trie
Picture a tree where each node is a character. The path from root to any node spells out a prefix or complete word.
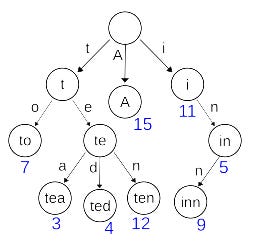
Each node contains:
Character value
Children pointers
Word completion flag
Optional metadata (frequency, last used, etc.)
Real-World Applications
1. Network Routing
Modern routers use PATRICIA tries (a compressed variant) to route internet traffic:
IP addresses as binary paths
Longest prefix matching for routing decisions
Sub-microsecond lookups
Compact memory footprint
2. DNA Sequence Analysis
Bioinformatics uses tries to:
Find common genetic sequences
Identify mutations
Compare DNA samples
Track evolutionary changes
3. Machine Learning
Natural Language Processing uses tries for:
Feature extraction
N-gram modeling
Word embedding lookups
Language model optimization
Performance Analysis
Tries offer predictable performance characteristics that make them ideal for string operations.
Basic operations like insert, search, and delete all run in O(k) time, where k is the key length. This means performance scales with word length, not dataset size. -
The space complexity is O(ALPHABET_SIZE * k), as each character might need a new node with pointers to potential children. In practice, most nodes have few children, making the actual space usage much lower than the worst case.
When to Use Tries
Best For:
Prefix-based operations
Autocomplete systems
Spell checkers
IP routing
Large-scale string dictionaries
Avoid When:
Random access is primary operation
Strings have minimal common prefixes
Memory is extremely constrained
Dataset is small and static
LeetCode questions on tries
Conclusion
Tries are powerful yet simple. They excel at string operations, making them perfect for modern applications like autocomplete and spell checking. With growing datasets and need for faster searches, tries offer an efficient solution that's here to stay.
Found any mistakes? Have suggestions for additional examples or topics you'd like me to cover? Drop a comment below!
I'm constantly looking to improve and make these explanations more helpful. Whether you're a beginner or an experienced developer, your insights help make this content better for everyone.
Well explained ❤️😍